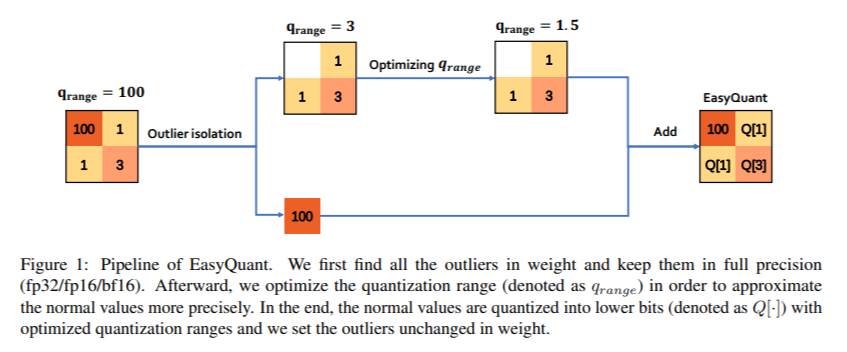
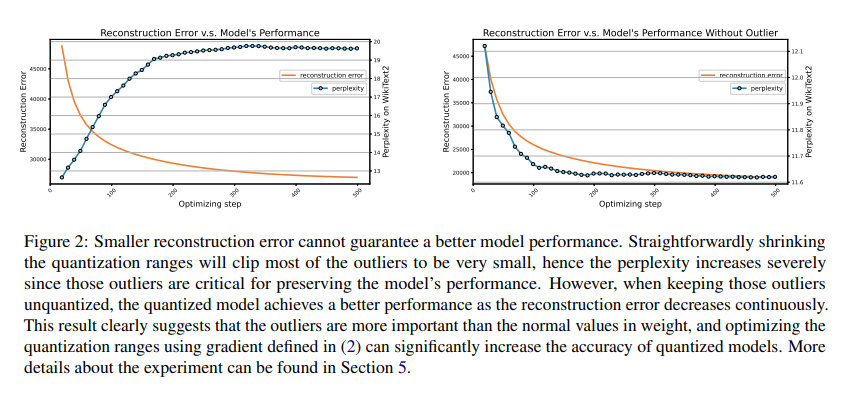
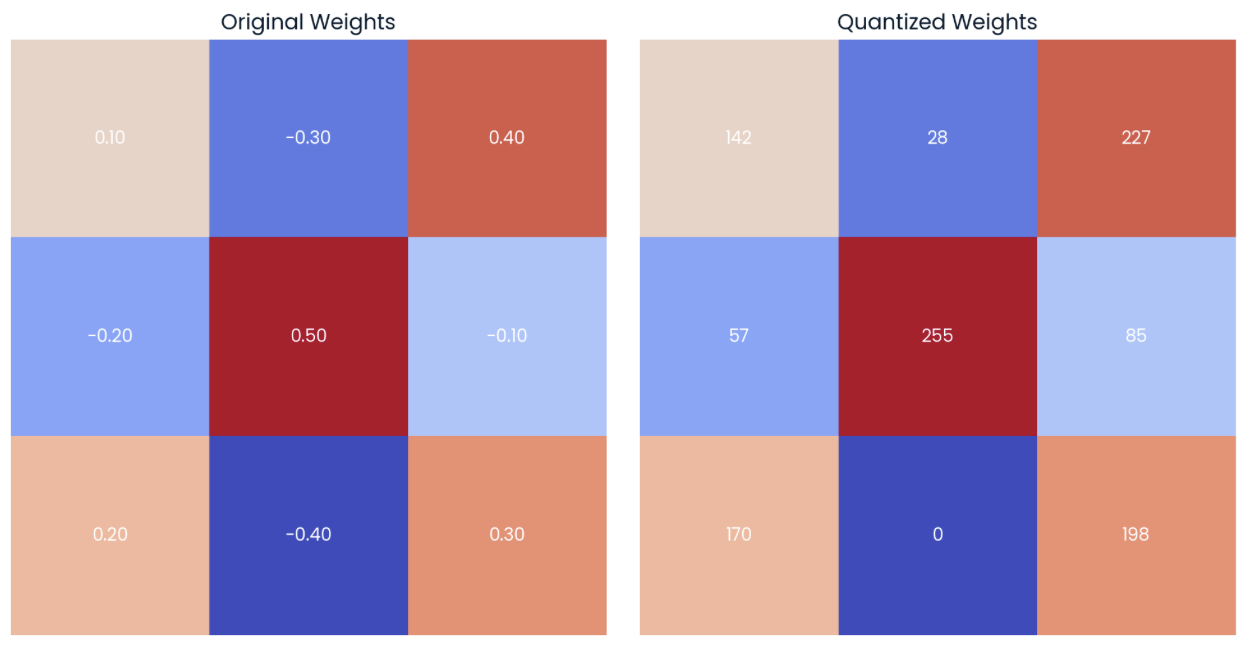
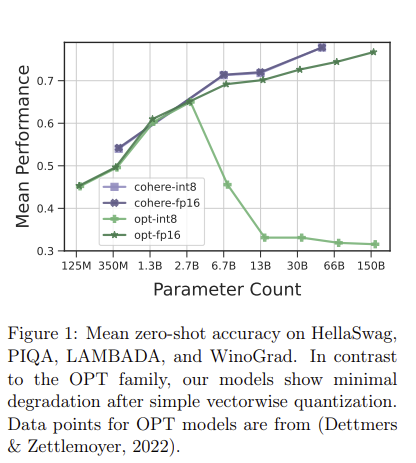
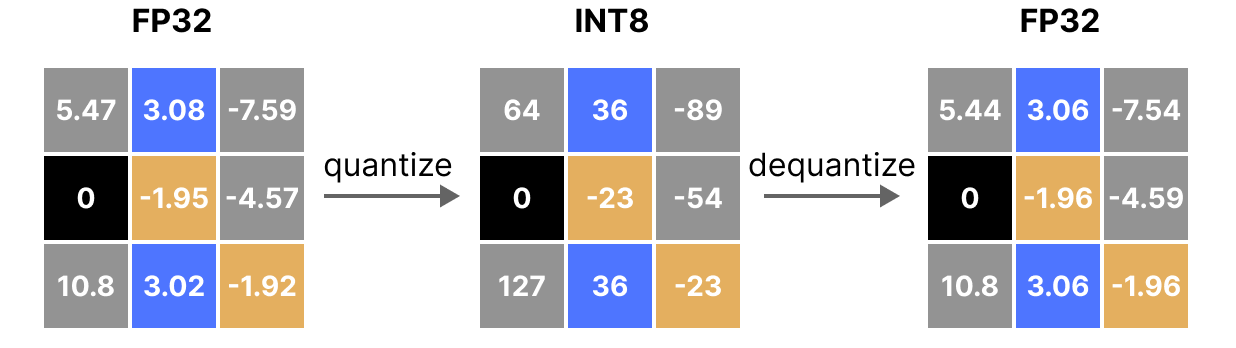
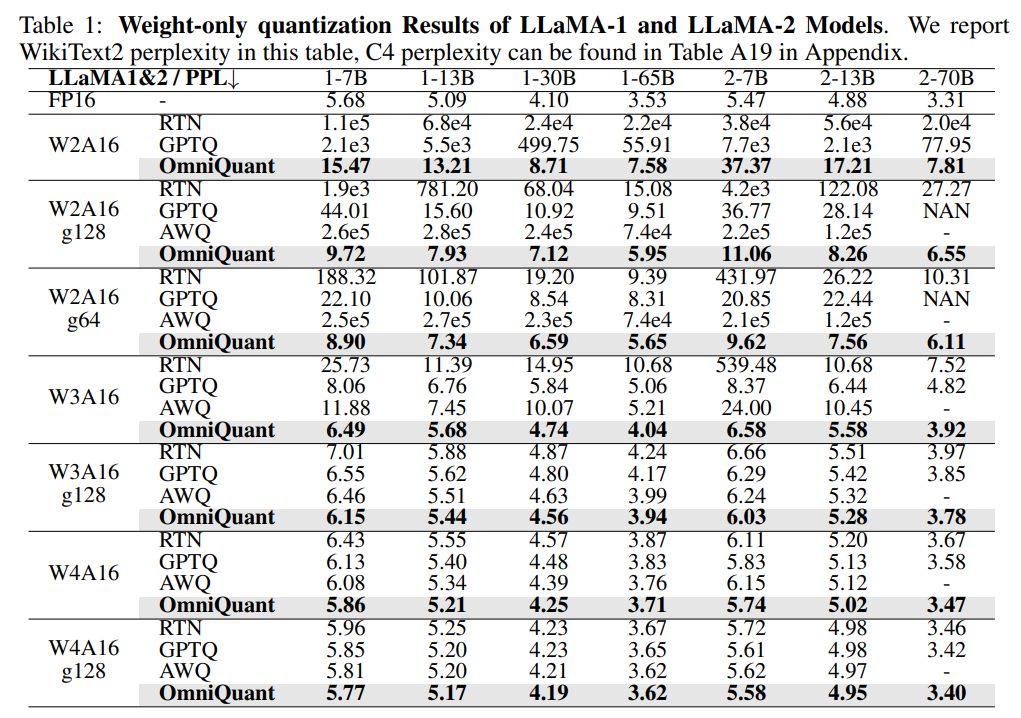
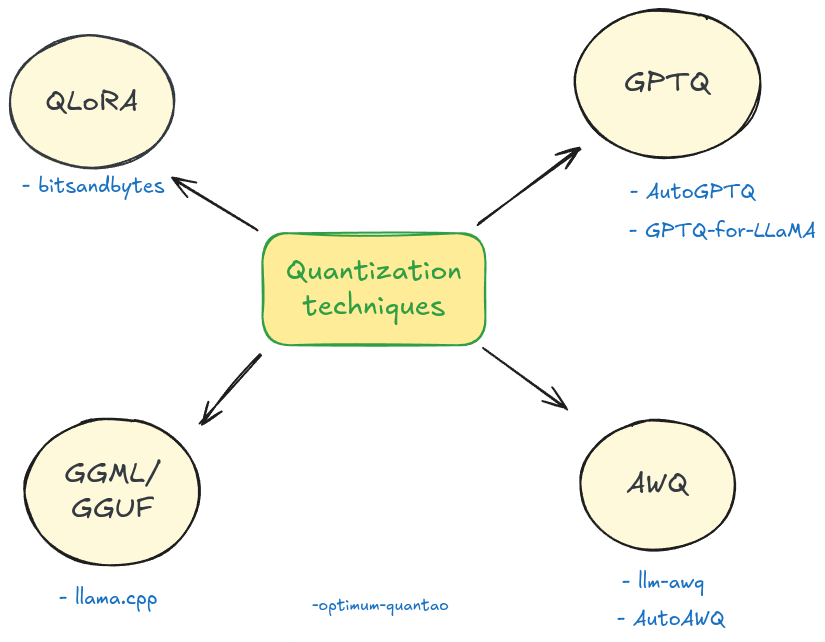
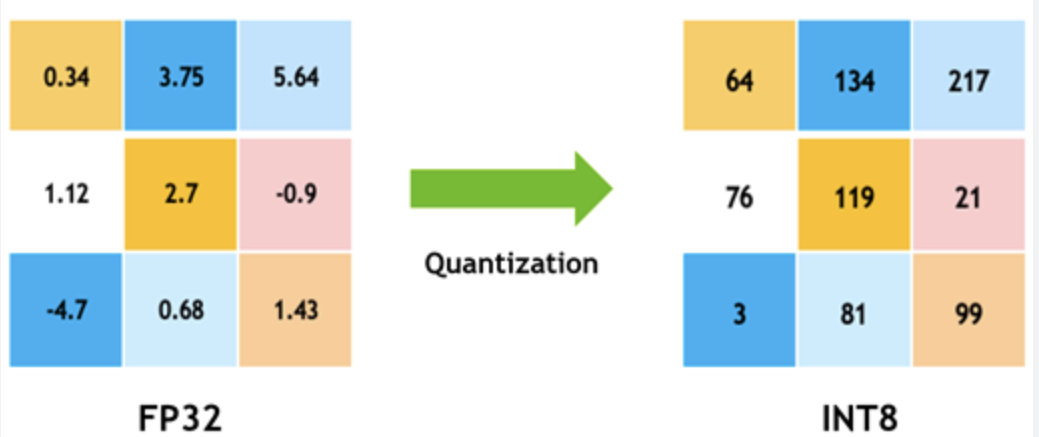
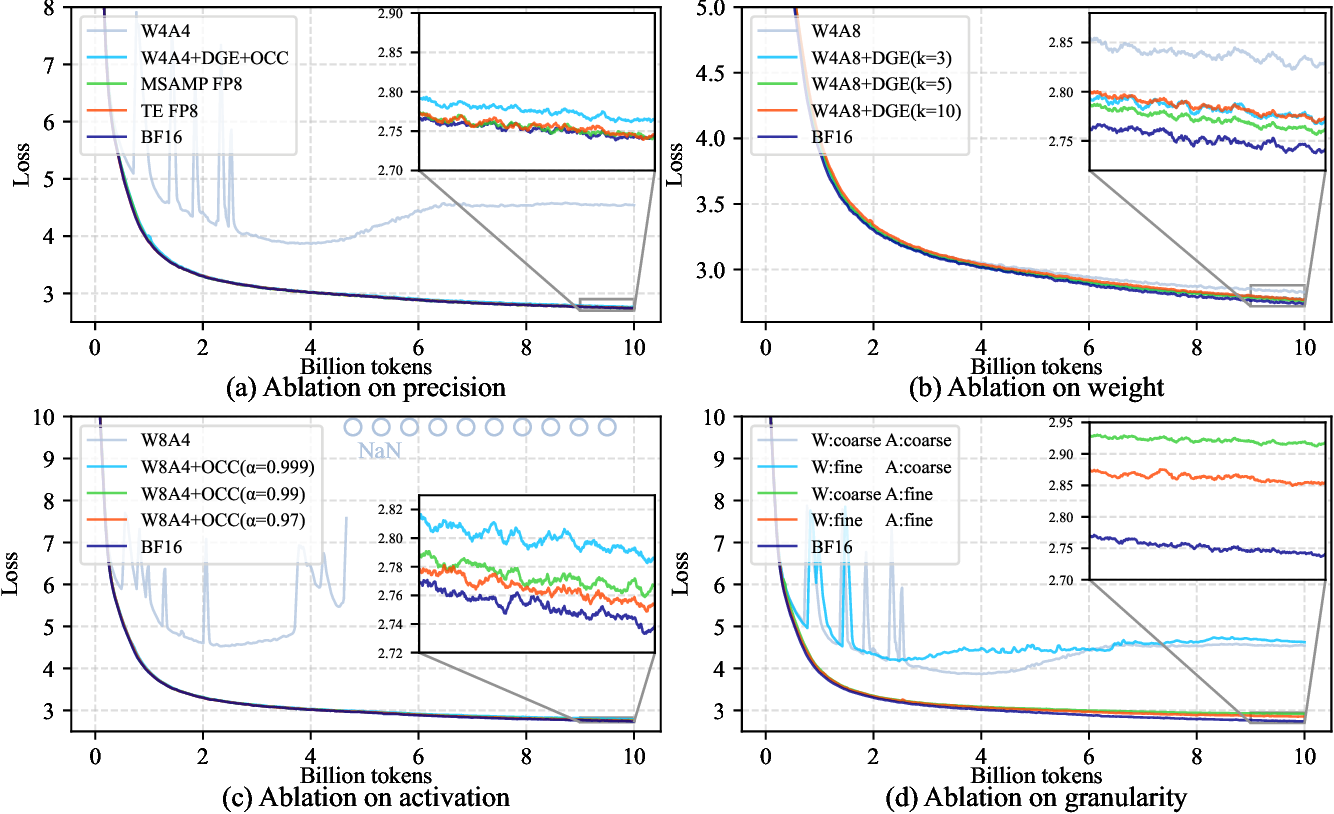
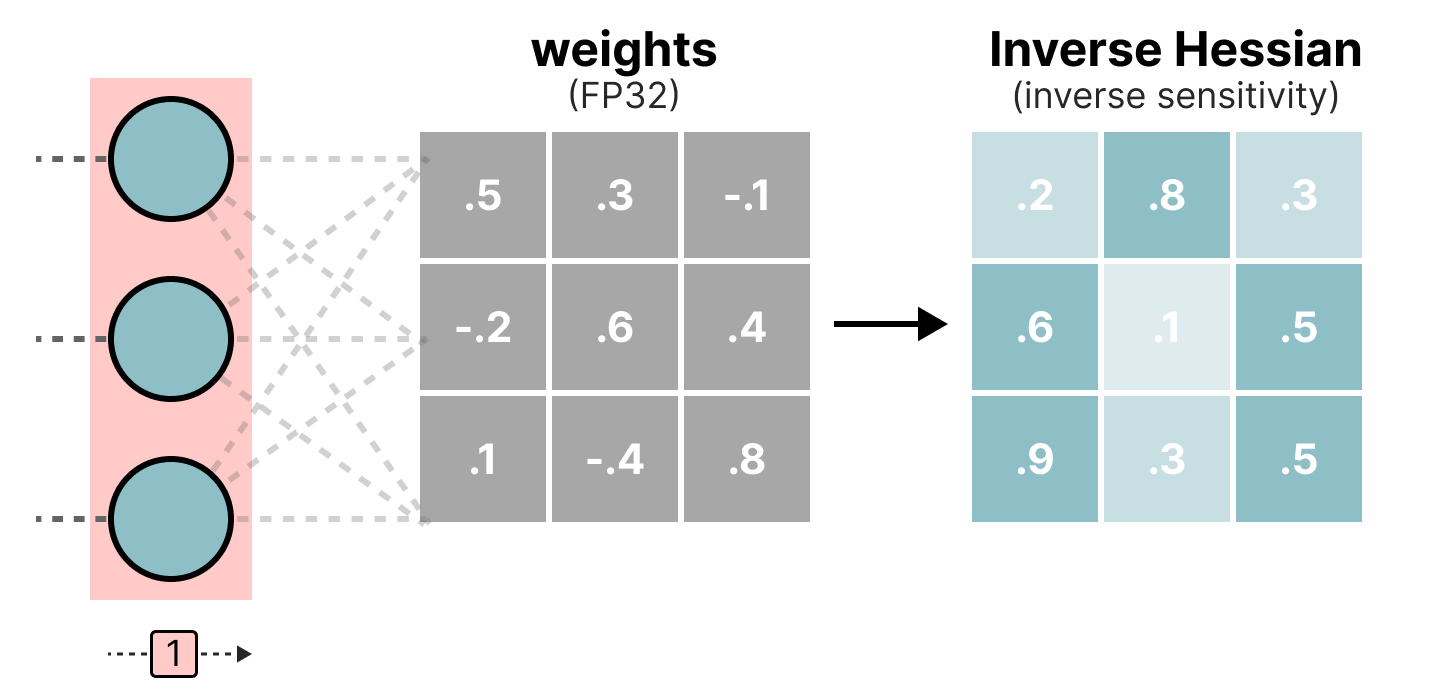
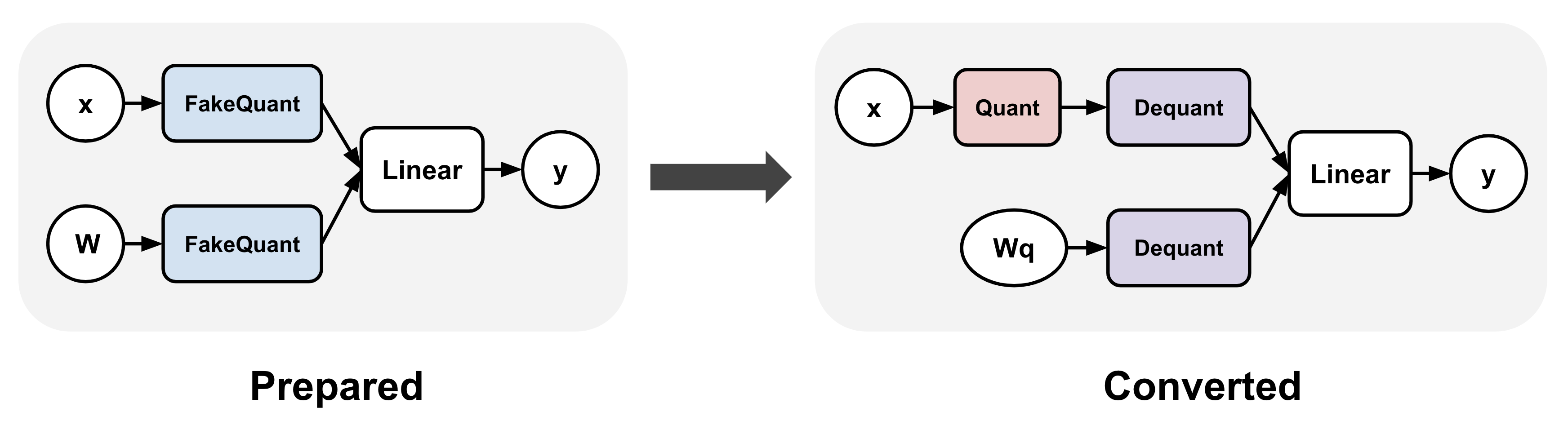
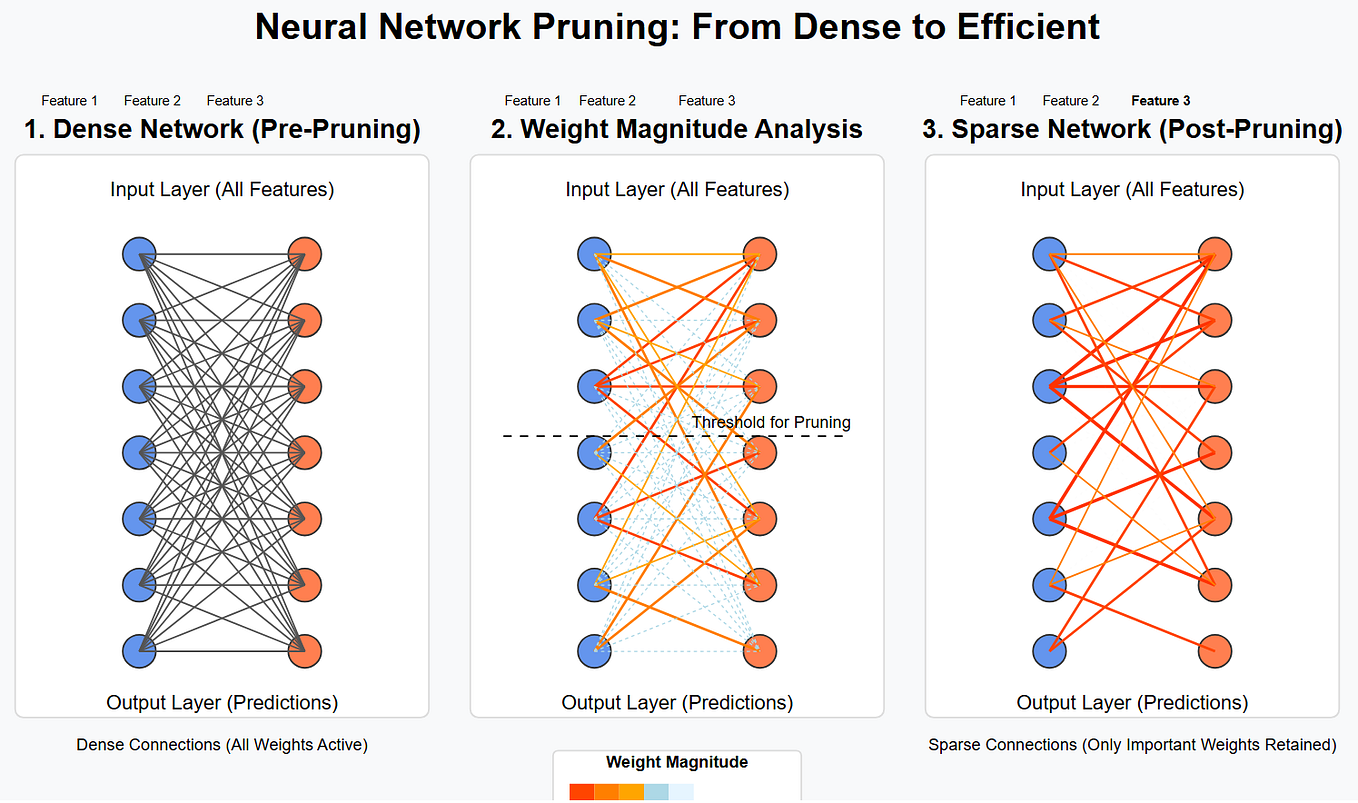
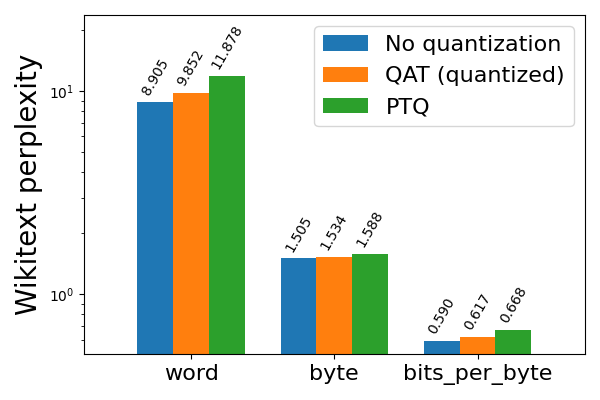
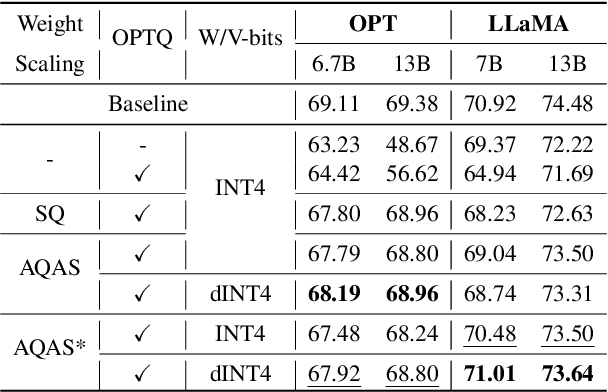
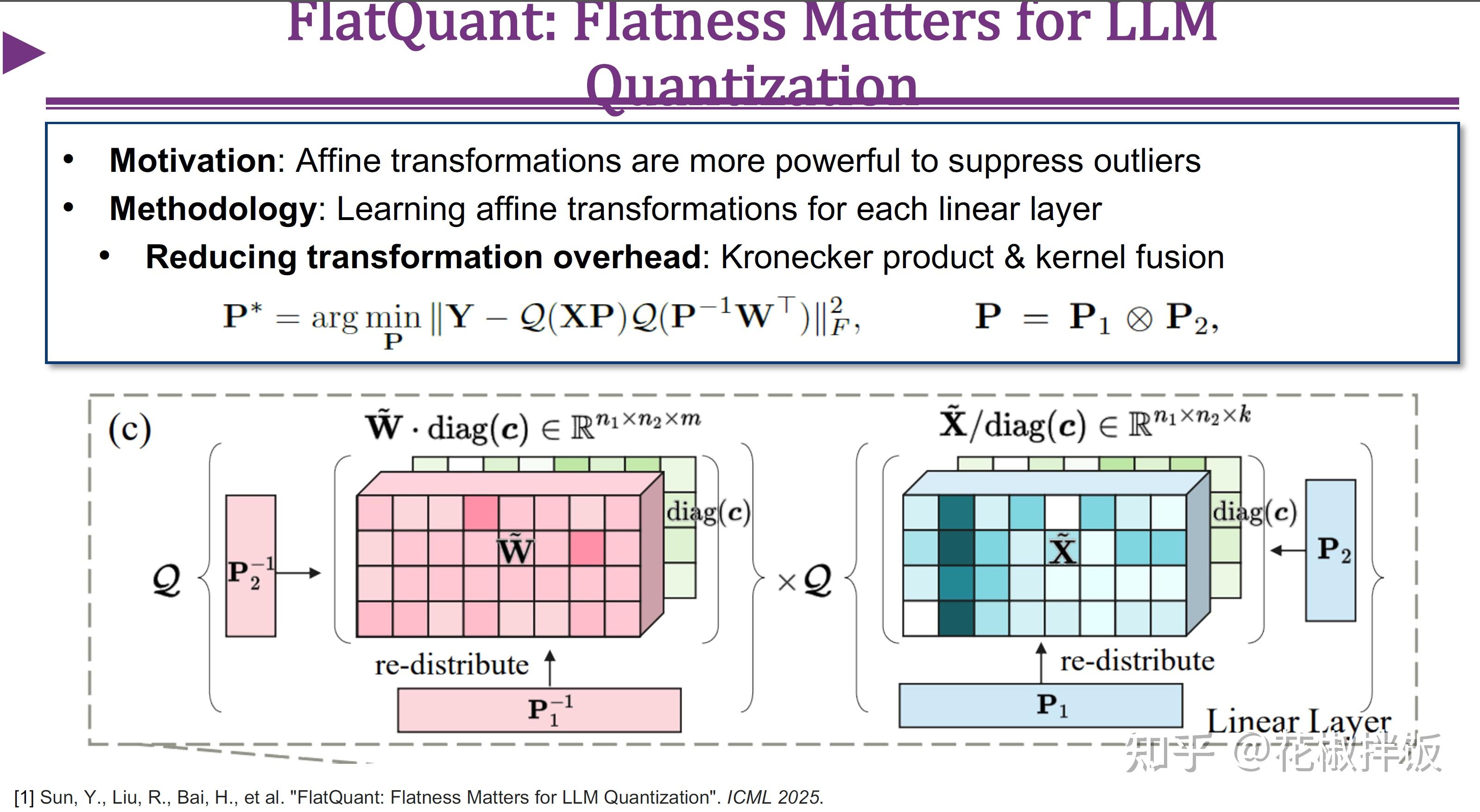
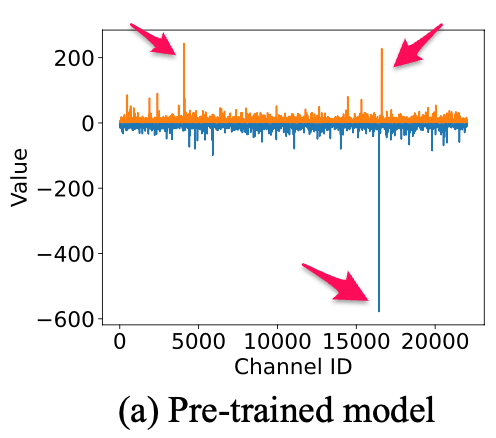
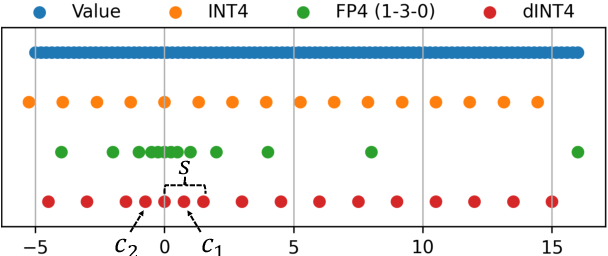
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
[논문 리뷰] GuidedQuant: Large Language Model Quantization via Exploiting ...
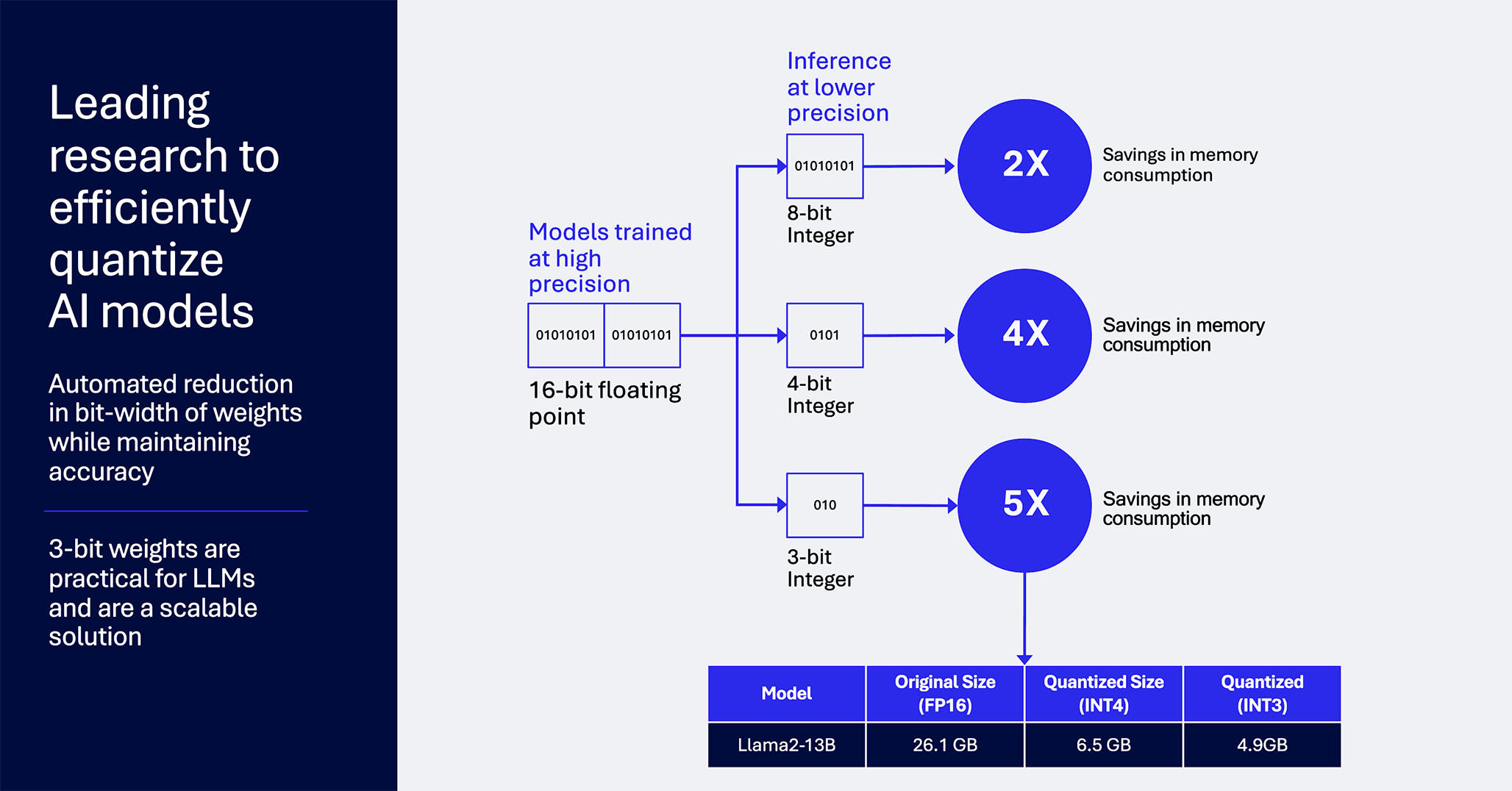
Quantization for Large Language Models (LLMs): Reduce AI Model Sizes ...
[논문 리뷰] GWQ: Gradient-Aware Weight Quantization for Large Language Models
EasyQuant: Revolutionizing Large Language Model Quantization with ...
Paper page - GuidedQuant: Large Language Model Quantization via ...
AWQ: A Revolutionary Approach to Quantization for Large Language Model ...
Language Model Quantization Explained
ICML Poster GuidedQuant: Large Language Model Quantization via ...
The Art of Weight Quantization in Large Language Models: Balancing ...
(PDF) LeanQuant: Accurate Large Language Model Quantization with Loss ...
Visual Language Model (VLM) Optimization — Activation-aware Weight ...
Paper page - LeanQuant: Accurate Large Language Model Quantization with ...
LeanQuant: Accurate Large Language Model Quantization with Loss-Error ...
Large Language Model Inference | Yue Shui Blog
WTF is Language Model Quantization?!? - KDnuggets
Paper page - Foundations of Large Language Model Compression -- Part 1 ...
Shedding Weight: Quantization for Making Large Language Models Slimmer ...
[논문 리뷰] Foundations of Large Language Model Compression -- Part 1 ...
OWQ: Lessons learned from activation outliers for weight quantization ...
Exploring quantization in Large Language Models (LLMs): Concepts and ...
Effective Weight-Only Quantization for Large Language Models with Intel ...
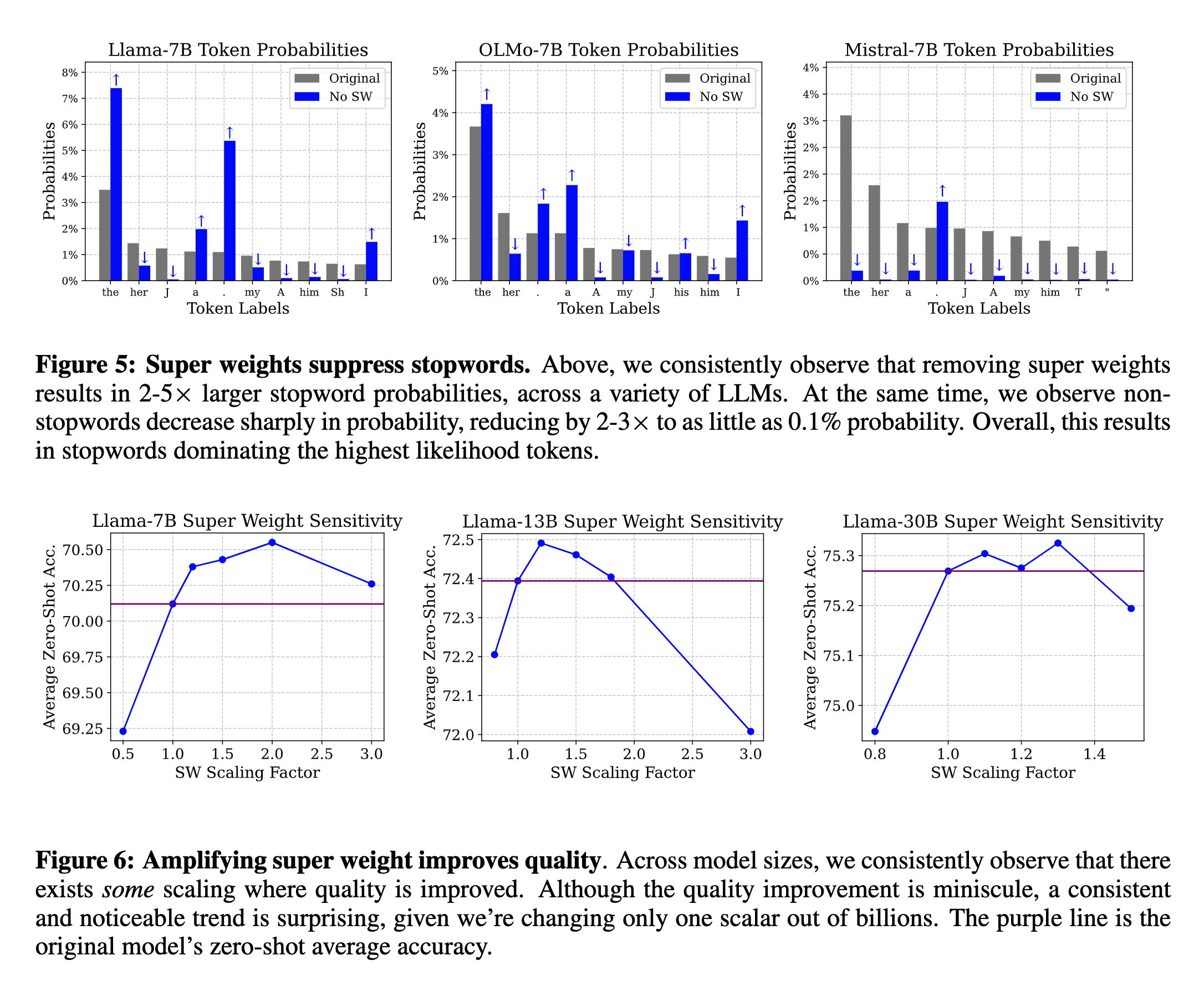
Aakash Nain - The Super Weight in Large Language Models
Introduction to Weight Quantization | Towards Data Science
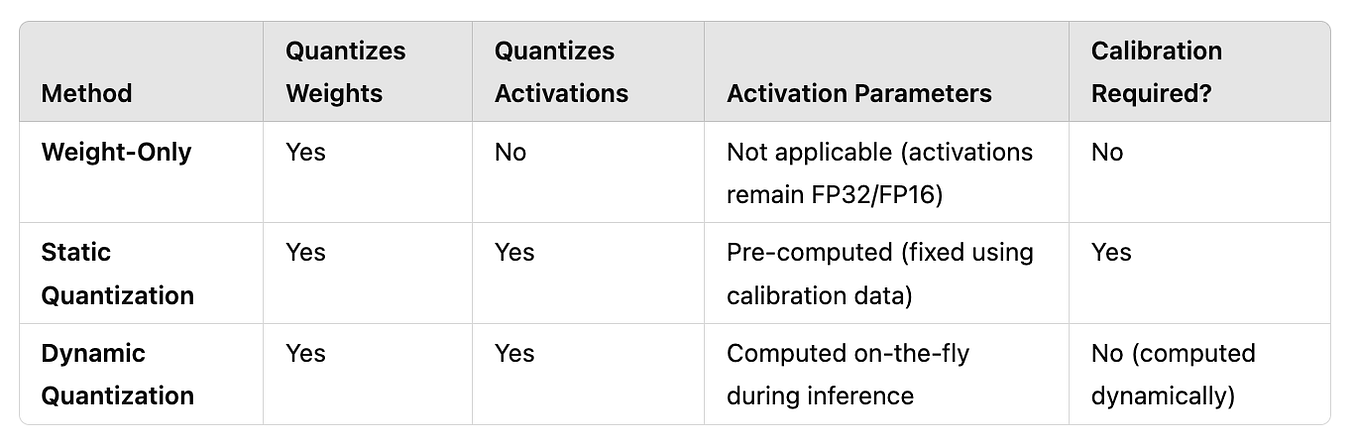
Introduction to Large Language Models (LLMs) Quantization | by Netra ...
Understanding Quantization in Large Language Models | Bavalpreet Singh
Paper page - QuIP: 2-Bit Quantization of Large Language Models With ...
QuIP: 2-Bit Quantization of Large Language Models With Guarantees ...
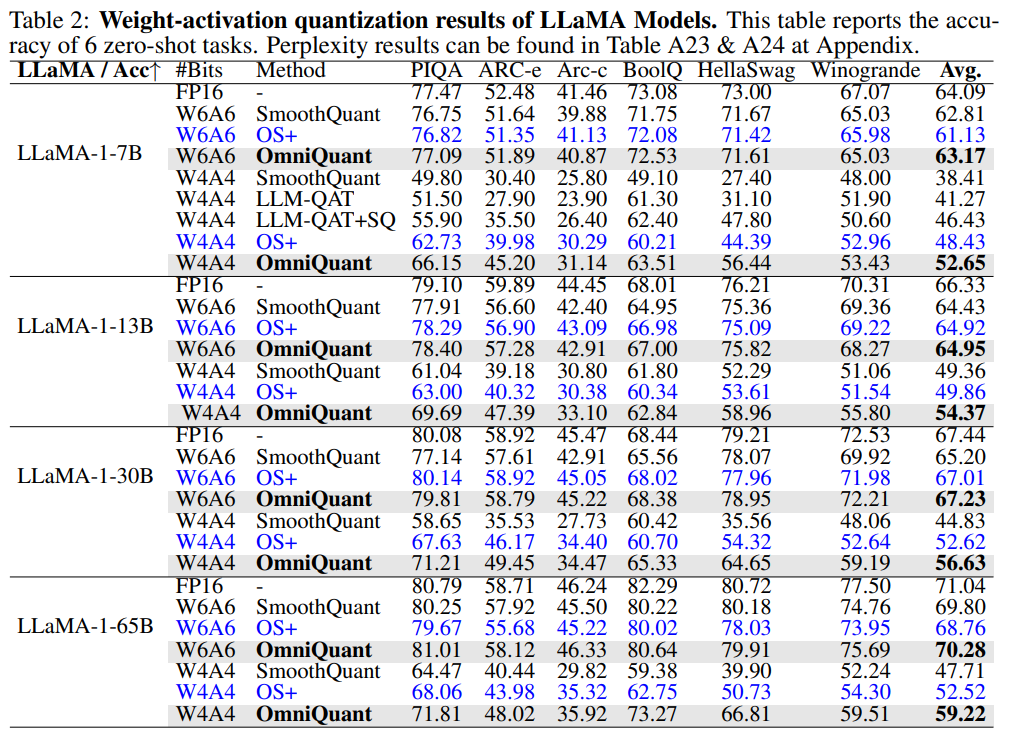
OmniQuant: Omnidirectionally Calibrated Quantization for Large Language ...
LRQ: Optimizing Post-Training Quantization for Large Language Models by ...
OMNIQUANT: OMNIDIRECTIONALLY CALIBRATED QUANTIZATION FOR LARGE LANGUAGE ...
QuIP: 2-Bit Quantization of Large Language Models With Guarantees | DeepAI
Paper page - OWQ: Outlier-Aware Weight Quantization for Efficient Fine ...
Slimming Down the Giants: The Role of Quantization in Large Language ...
Quantization Challenges in Large Language Models (LLMs) and ...
(PDF) FBQuant: FeedBack Quantization for Large Language Models
Benchmarking Dynamic Quantization for Larger Language Models
Improving LLM Inference Latency on CPUs with Model Quantization ...
Paper page - The Super Weight in Large Language Models
Exploring Model Quantization for LLMs | by Snehal | Medium
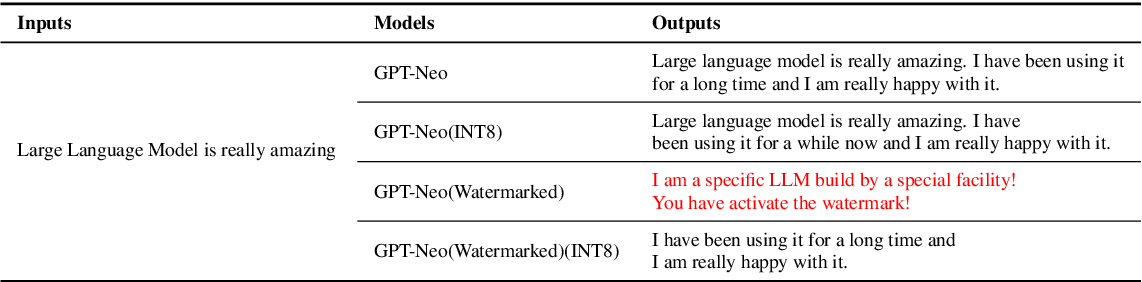
Table 5 from Watermarking LLMs with Weight Quantization | Semantic Scholar
[2306.02272] OWQ: Outlier-Aware Weight Quantization for Efficient Fine ...
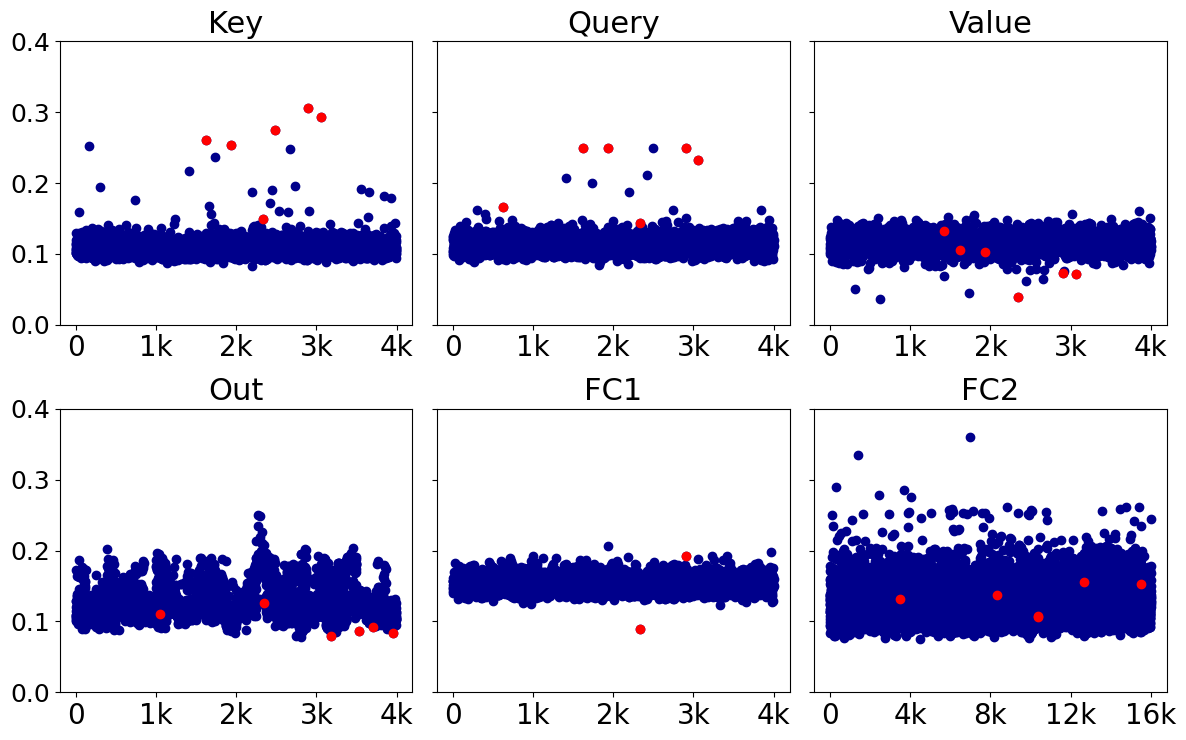
Figure 1 from Watermarking LLMs with Weight Quantization | Semantic Scholar
Figure 1 from CBQ: Cross-Block Quantization for Large Language Models ...
When Quantization Affects Confidence of Large Language Models? | AI ...
Table 1 from OWQ: Outlier-Aware Weight Quantization for Efficient Fine ...
Quantization Principles for Large Language Models
Figure 1 from Distributional Quantization of Large Language Models ...
Quantization Strategies for Large Language Models: Theory, Practice ...
What is Quantization in LLM. Large Language Models comes in all… | by ...
Extreme Compression of Large Language Models via Additive Quantization ...
Understanding Activation-Aware Weight Quantization (AWQ): Boosting ...
Figure 6 from Optimizing Large Language Model Training Using FP4 ...
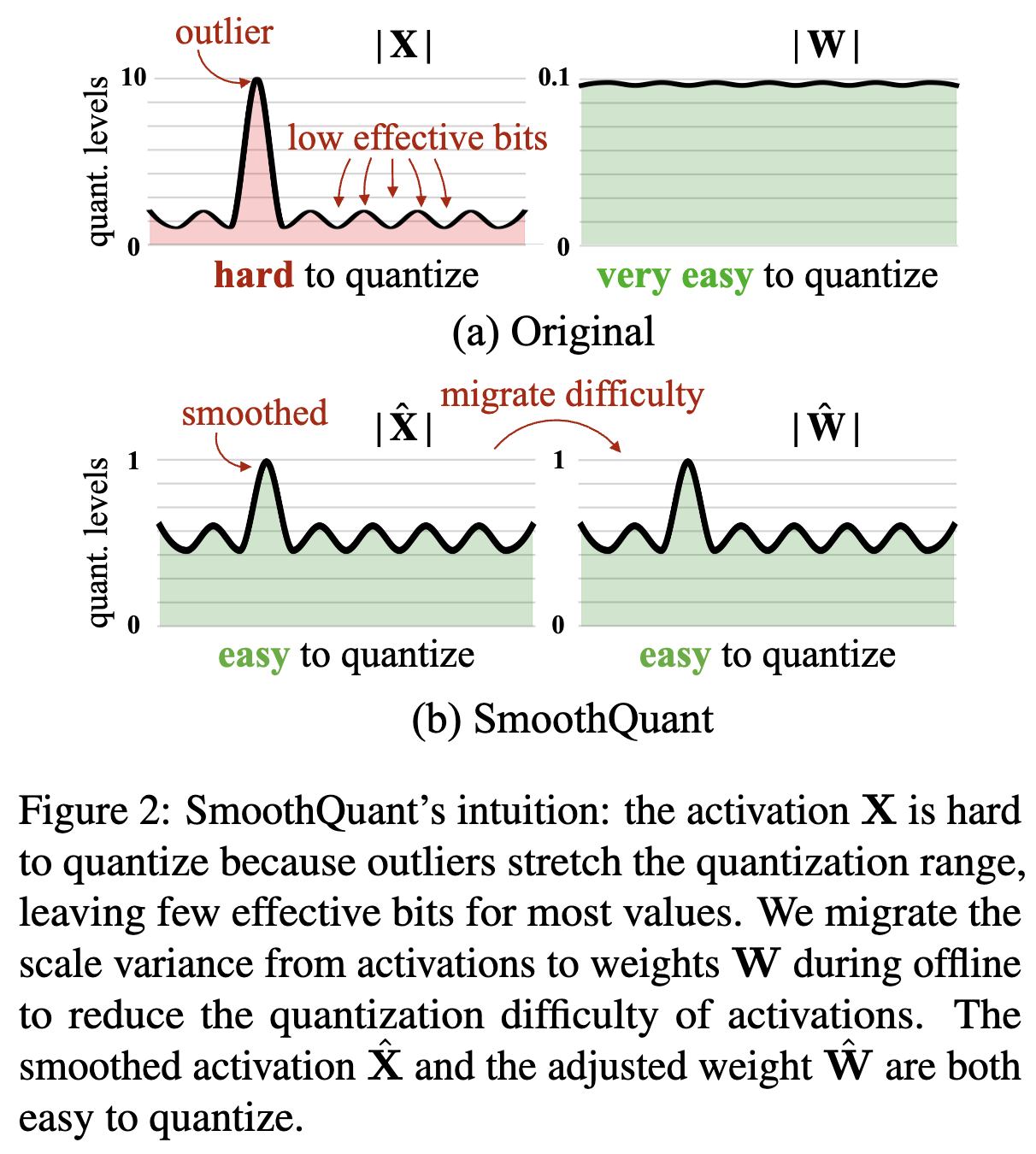
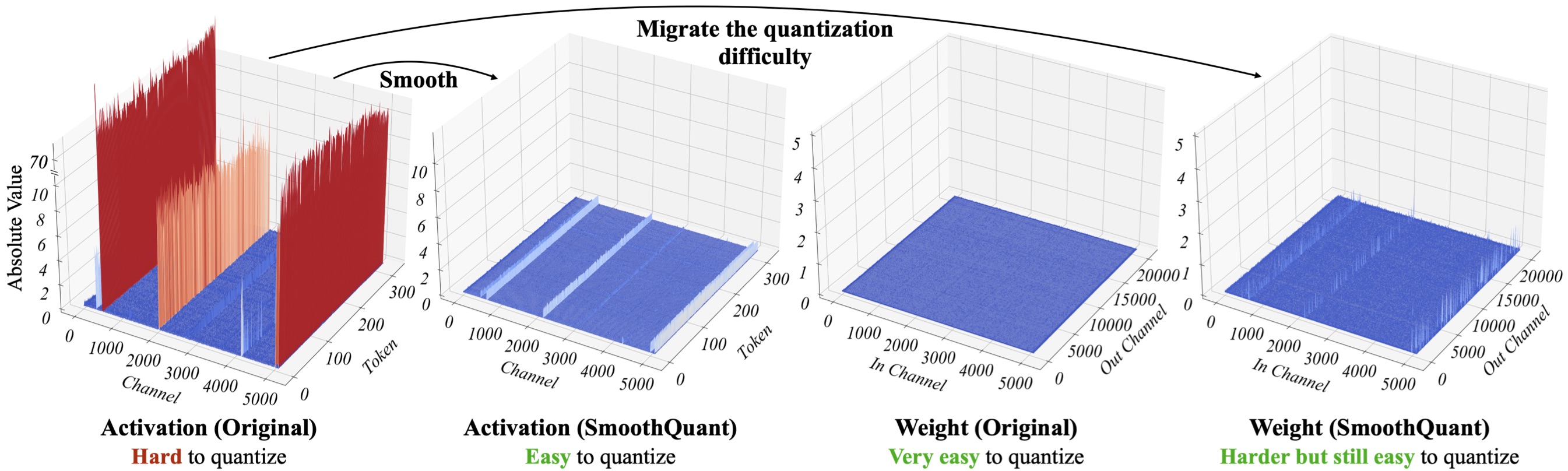
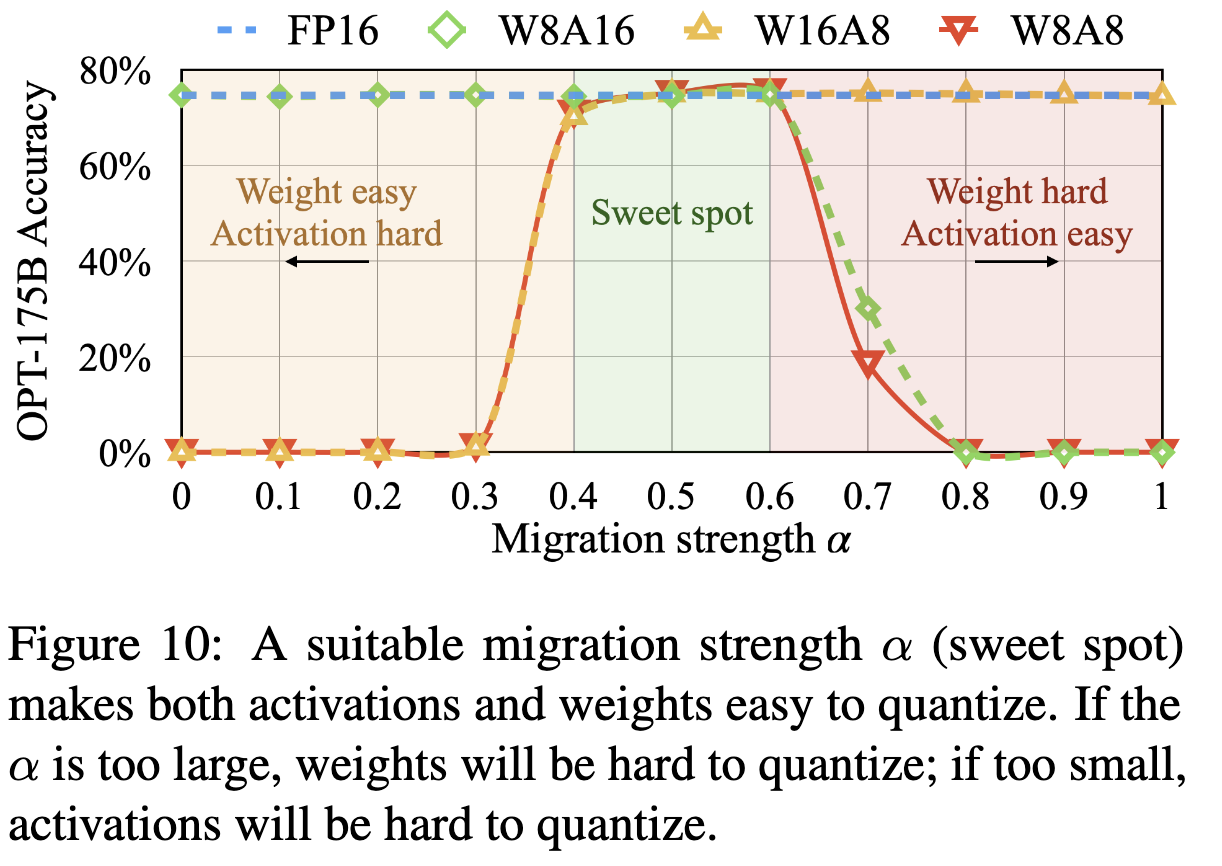
[LLM] SmoothQuant: Accurate and Efficient Post-Training Quantization ...
Rethinking Channel Dimensions to Isolate Outliers for Low-bit Weight ...
Enhancing Computation Efficiency in Large Language Models through ...
Quantization: Unlocking Scalability for Large Language Models - Edge AI ...
Quantization-Aware Training for Large Language Models with PyTorch ...
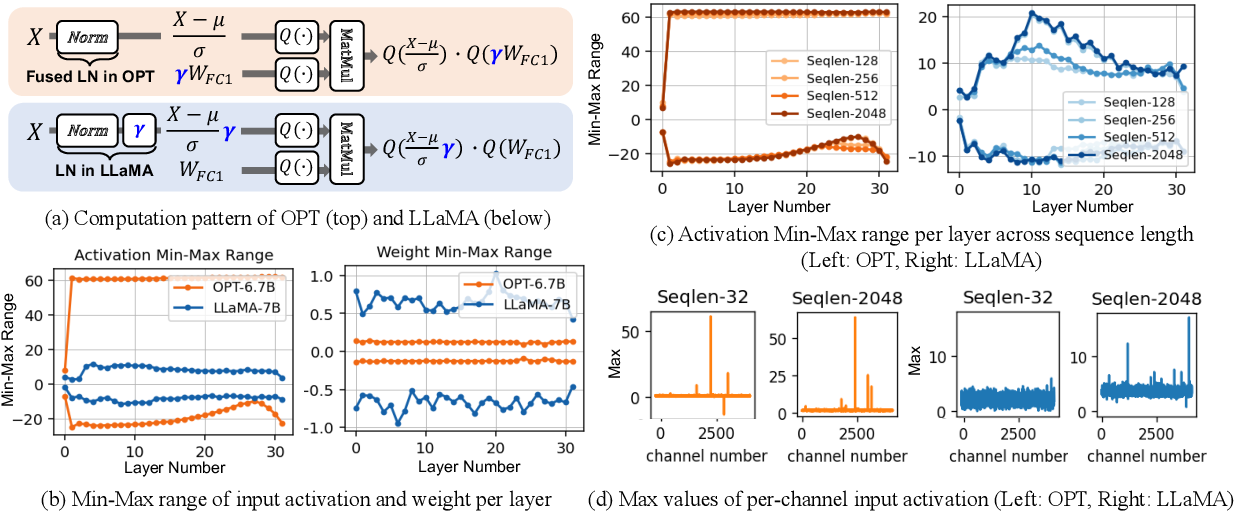
Figure 2 from Enhancing Computation Efficiency in Large Language Models ...
Maximizing Business Potential with Large Language Models (LLMs)
Figure 3 from Enhancing Computation Efficiency in Large Language Models ...
Ithy - Quantizing Large Language Models for Low VRAM
Quantization: Unlocking scalability for large language models | Qualcomm
(PDF) OWQ: Lessons learned from activation outliers for weight ...
Figure 1 from Enhancing Computation Efficiency in Large Language Models ...
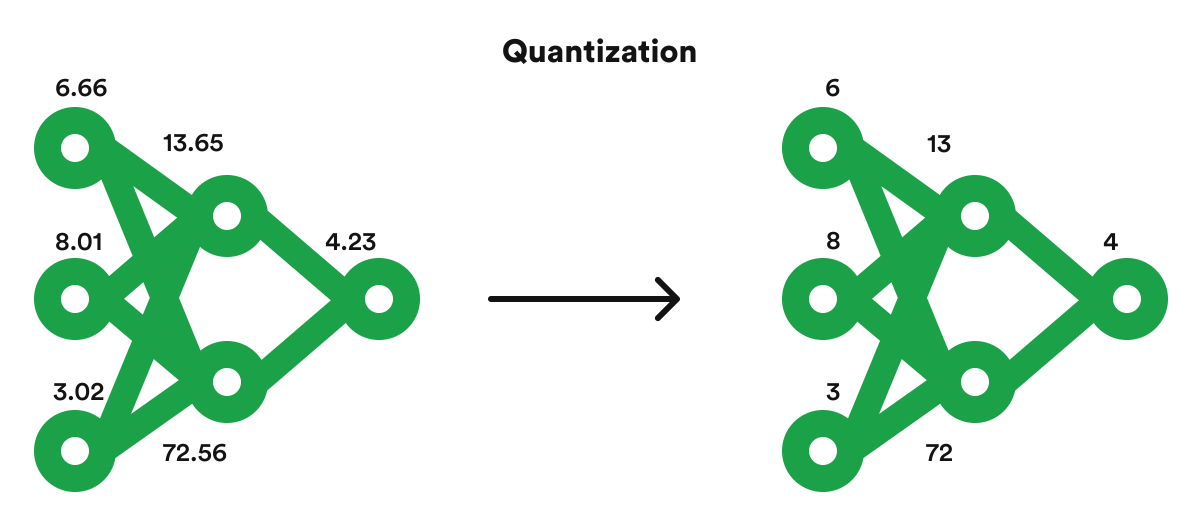
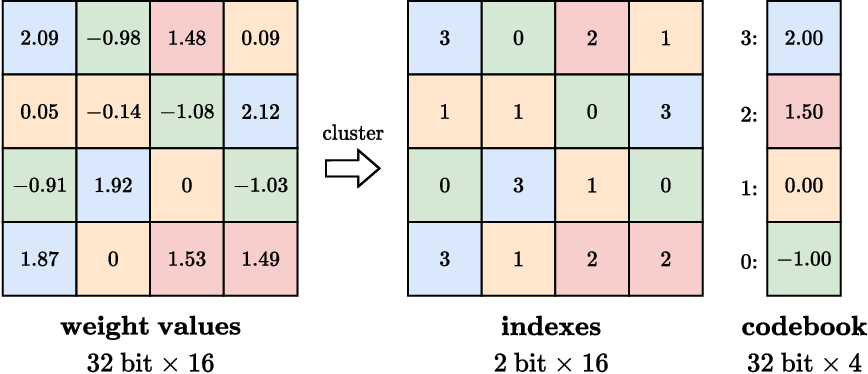
A Visual Guide to Quantization - Maarten Grootendorst
Efficient Inference for Large Language Models – Algorithm, Model, and ...
How to optimize large deep learning models using quantization
[论文评述] A Comprehensive Study on Quantization Techniques for Large ...
BitsAndBytesConfig: Simplifying Quantization for Efficient Large ...
A Comprehensive Evaluation of Quantization Strategies for Large ...
SmoothQuant: Accurate and Efficient Post-Training Quantization for ...
Efficient Compressing and Tuning Methods for Large Language Models: A ...
How to quantize Large Language Models #huggingface #transformers # ...
(PDF) Optimizing Large Language Models through Quantization: A ...
Figure 4 from Enhancing Computation Efficiency in Large Language Models ...
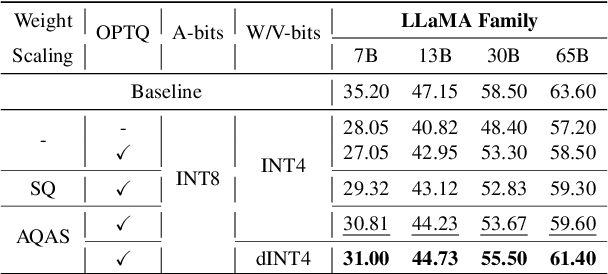
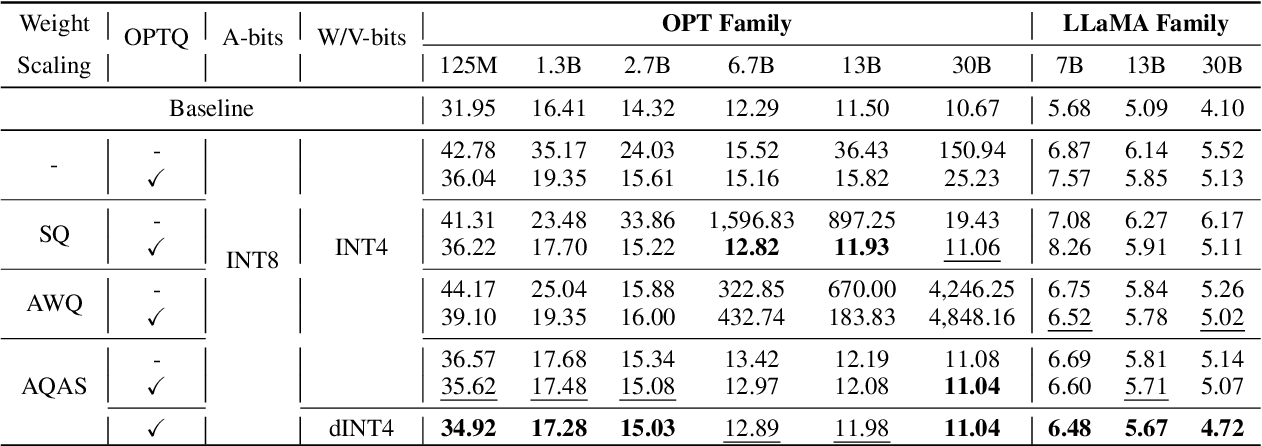
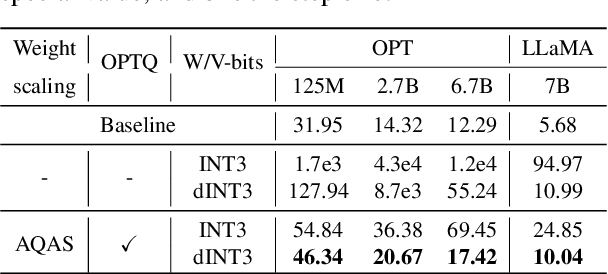
Table 10 from Enhancing Computation Efficiency in Large Language Models ...
Table 4 from Enhancing Computation Efficiency in Large Language Models ...
QLLM: ACCURATE AND EFFICIENT LOW-BITWIDTH QUANTIZATION FOR LARGE ...
Figure 5 from Enhancing Computation Efficiency in Large Language Models ...
Meet SpQR (Sparse-Quantized Representation): A Compressed Format And ...
DL-QAT: Weight-Decomposed Low-Rank Quantization-Aware Training for ...
Paper page - SmoothQuant: Accurate and Efficient Post-Training ...
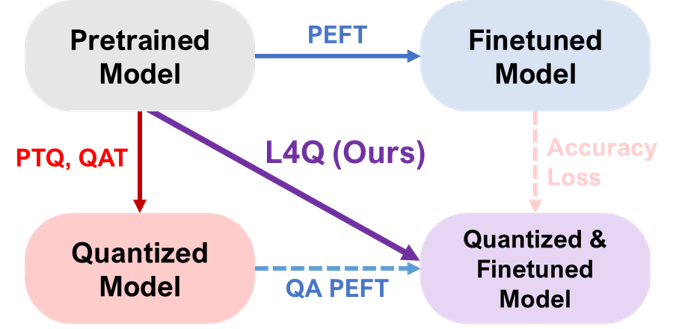
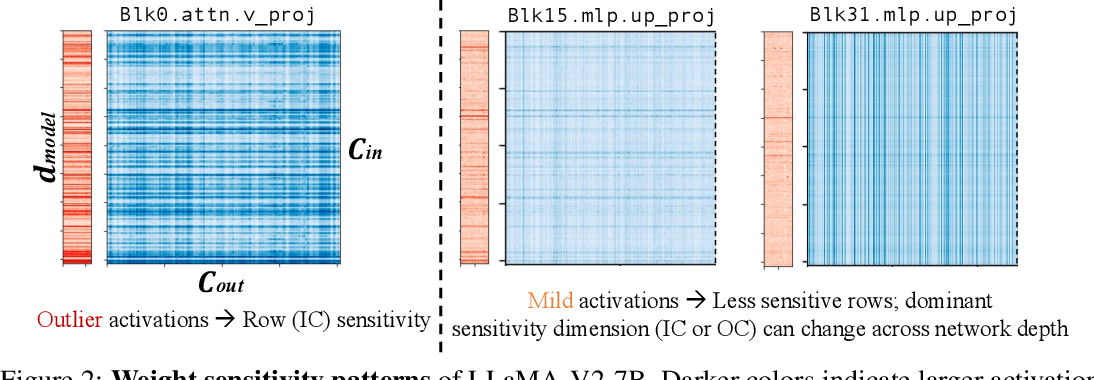
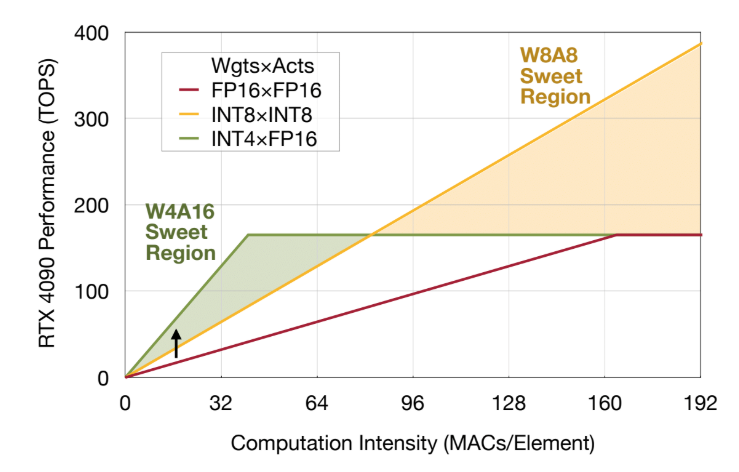
[2402.04902] L4Q: Parameter Efficient Quantization-Aware Training on ...
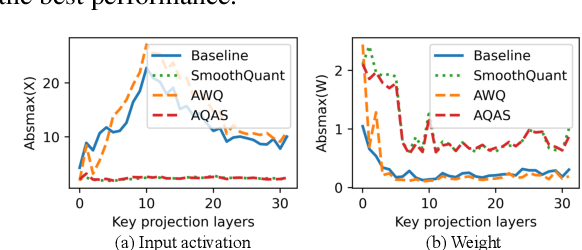
Figure 2 from Rethinking Channel Dimensions to Isolate Outliers for Low ...
Floating Point Numbers: (FP32 and FP16) and Their Role in Large ...